Ha llegado el tan esperado momento. Tras múltiples artículos explicando los fundamentos de redes neuronales ya hemos obtenido las bases necesarias para empezar a entender de manera definitiva y al detalle cómo se puede construir una herramienta como ChatGPT. Si bien ya sabemos bastante sobre el funcionamiento de redes neuronales, los grandes modelos de lenguaje combinan todos los conocimientos que hemos visto usando una lógica bastante abstracta e interesante.
En esta explicación iremos al grano y hablaremos de cómo funcionan los transformers. De hecho, el significado de GPT es “Generative Pre-trained Transformer”. Veremos el concepto de los transformers a lo largo de varios artículos. En este artículo hablaremos de vectores, tokens y embeddings. En futuros artículos hablaremos depositional embedding, mecanismos de atención, toda la arquitectura de los transformers y cómo escalar grandes modelos de lenguaje.
Además, a lo largo de este artículo entenderás por qué todo el mundo le da tanta importancia al número de parámetros de los modelos de lenguaje. Seguro que has escuchado alguna vez… ¡GPT-4 tendrá X veces más parámetros que GPT-3! ¿Impresionado? Bueno, para que algo te impresione de verdad, mejor entenderlo.
[powerkit_toc title=»Table of Contents» depth=»2″ min_count=»1″ min_characters=»1000″ btn_hide=»false» default_state=»expanded»]
Vectores y tokens. La representación vectorial del vocabulario.
Si buscas por ahí la definición de un vector probablemente encuentres algo como que es una entidad matemática que “es una flecha” o una dirección o una línea en un espacio 2D o 3D… Y lo cierto es que sí, los vectores se utilizan para representar todo eso, pero para aplicar vectores en inteligencia artificial debemos utilizarlos para representar conceptos más complejos, abstractos e incluso dejar que las redes neuronales decidan darle la representación que quieran. Y con esto que te digo tengo un cierto dilema. Verás, explicar vectores desde un punto de vista geométrico es mucho más entendible y por ello lo haré así. Sólo te pido que a lo largo del artículo no te olvides de lo siguiente:
Un vector es un conjunto de valores numéricos. Utilizaremos vectores para representar todo tipo de cosas, especialmente magnitudes de propiedades. En un espacio 2D, un vector se representa mediante dos valores, generalmente denotados como (x, y). Cada uno de estos valores indica la posición del vector en relación con un punto de origen (0, 0) en un plano bidimensional. Por ejemplo, el vector (3, 4) representa una posición que está 3 unidades a lo largo del eje x (horizontal) y 4 unidades a lo largo del eje y (vertical).
A continuación voy a graficar un ejemplo de un vector con los valores (3,4). Y entenderás por qué se dice que un vector puede representar una «flecha», una dirección o una velocidad.
# Importamos las bibliotecas necesariasimport numpy as npimport matplotlib.pyplot as plt# Creamos un vector 2Dvector_2d = np.array([3, 4])# Graficamos el vector 2Dplt.quiver(0, 0, vector_2d[0], vector_2d[1], angles=’xy’, scale_units=’xy’, scale=1, color=’r’)plt.xlim(-1, 5)plt.ylim(-1, 5)plt.xlabel(«Eje X»)plt.ylabel(«Eje Y»)plt.grid()plt.title(«Representación gráfica de un vector 2D»)plt.show()

# Importamos las bibliotecas necesariasimport numpy as npimport matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3D# Creamos un vector 3Dvector_3d = np.array([2, 3, 4])# Creamos la figura y el objeto Axes3Dfig = plt.figure()ax = fig.add_subplot(111, projection=’3d’)# Graficamos el vector 3Dax.quiver(0, 0, 0, vector_3d[0], vector_3d[1], vector_3d[2], color=’b’)ax.set_xlim([0, 5])ax.set_ylim([0, 5])ax.set_zlim([0, 5])ax.set_xlabel(«Eje X»)ax.set_ylabel(«Eje Y»)ax.set_zlabel(«Eje Z»)ax.set_title(«Representación gráfica de un vector 3D»)plt.show()

Supongamos que te he dicho la palabra «Papá».
Y tú has realizado la siguiente puntuación: Formalidad: 3 Frecuencia: 8 Positividad: 6
Si te fijas, todas estas características que representan a la palabra «Papá», se pueden meter dentro de un vector con los valores (3,8,6).
Y si graficamos este vector, nos quedaría algo así:
# Importamos las bibliotecas necesariasimport numpy as npimport matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3D# Creamos un vector 3D para la palabra «Papá»palabra_papa = np.array([3, 8, 6])# Creamos la figura y el objeto Axes3Dfig = plt.figure()ax = fig.add_subplot(111, projection=’3d’)# Graficamos el vector 3Dax.quiver(0, 0, 0, palabra_papa[0], palabra_papa[1], palabra_papa[2], color=’r’, label=’Papá’)ax.set_xlim([-1, 10])ax.set_ylim([-1, 10])ax.set_zlim([-1, 10])ax.set_xlabel(«Formalidad»)ax.set_ylabel(«Frecuencia de uso»)ax.set_zlabel(«Positividad»)ax.set_title(«Representación gráfica de vector 3D para propiedades de la palabra ‘Papá'»)ax.legend()plt.show()

# Importamos las bibliotecas necesariasimport numpy as npimport matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3D# Creamos vectores 3D para 10 palabras diferentespalabras = {‘Amor’: np.array([2, 9, 8]),‘Odio’: np.array([8, 7, 1]),‘Trabajo’: np.array([5, 8, 5]),‘Vacaciones’: np.array([2, 4, 9]),‘Estudio’: np.array([4, 6, 7]),‘Juego’: np.array([1, 5, 9]),‘Perro’: np.array([3, 7, 7]),‘Gato’: np.array([3, 6, 7]),‘Luz’: np.array([3, 5, 8]),‘Sombra’: np.array([6, 4, 4])}# Creamos la figura y el objeto Axes3Dfig = plt.figure()ax = fig.add_subplot(111, projection=’3d’)# Graficamos los vectores 3Dcolores = [‘r’, ‘g’, ‘b’, ‘c’, ‘m’, ‘y’, ‘k’, ‘orange’, ‘purple’, ‘brown’]for i, (palabra, vector) in enumerate(palabras.items()):ax.quiver(0, 0, 0, vector[0], vector[1], vector[2], color=colores[i], label=palabra)ax.set_xlim([-1, 10])ax.set_ylim([-1, 10])ax.set_zlim([-1, 10])ax.set_xlabel(«Formalidad»)ax.set_ylabel(«Frecuencia de uso»)ax.set_zlabel(«Positividad»)ax.set_title(«Representación gráfica de vectores 3D para propiedades de 10 palabras»)ax.legend()plt.show()

Claramente, la dirección del vector y la magnitud de cada palabra variará entre cada persona. Pero en el lenguaje todas las propiedades a gran escala coinciden. Claro está, 3 propiedades son muy pocas como para definir con un vector el significado de una palabra a un nivel de detalle muy preciso.
Por ello, sería mejor añadir muchas más propiedades. Por ejemplo, podríamos puntuar qué tan ofensiva es una palabra, o que tan tropical, o qué tan intelectual…
Con la cantidad suficiente de propiedades (cantidad de valores del vector) mejor y con más detalle podemos representar palabras con vectores.
¡Y eso es precisamente lo que hacen las redes neuronales para procesar lenguaje natural! Las redes neuronales no entienden de secuencias de caracteres (o al menos no hasta que hablemos de positional embedding, pero a eso llegaremos más tarde). A éstos vectores que representan palabras se les llama tokens.
Pero antes de continuar explicando cómo se procesa el lenguaje natural en una red neuronal quiero terminar de explicar la base de los vectores. Para ello necesito que sepas qué es un vector normalizado.
Un vector normalizado es aquel que ha sido escalado de tal manera que su longitud o magnitud sea igual a 1, pero su dirección permanece igual. La normalización de un vector es un proceso que nos permite comparar y trabajar con vectores de diferentes magnitudes en términos de dirección. Esto es útil en muchos contextos, como en el análisis de datos y en el procesamiento de señales, donde la dirección de un vector es más importante que su magnitud.
Para normalizar un vector, dividimos cada componente del vector por su magnitud. La magnitud de un vector se calcula como la raíz cuadrada de la suma de los cuadrados de sus componentes.
A continuación te muestro un ejemplo de un vector no normalizado y su versión normalizada:
# Importamos las bibliotecas necesariasimport numpy as npimport matplotlib.pyplot as plt# Creamos un vector no normalizado y lo normalizamosvector_no_normalizado = np.array([3, 4])magnitud = np.linalg.norm(vector_no_normalizado)vector_normalizado = vector_no_normalizado / magnitud# Graficamos el vector no normalizado y el normalizadoplt.quiver(0, 0, vector_no_normalizado[0], vector_no_normalizado[1], angles=’xy’, scale_units=’xy’, scale=1, color=’r’, label=’No normalizado’)plt.quiver(0, 0, vector_normalizado[0], vector_normalizado[1], angles=’xy’, scale_units=’xy’, scale=1, color=’b’, label=’Normalizado’)plt.xlim(-0.5, 3.5)plt.ylim(-0.5, 4.5)plt.xlabel(«Eje X»)plt.ylabel(«Eje Y»)plt.grid()plt.title(«Comparación entre un vector no normalizado y uno normalizado»)plt.legend()plt.show()

Dicho esto, imagina que yo te pido que expreses matemáticamente qué tan diferente es la palabra «Odio» de la palabra «Amor».
Y nosotros representamos las palabras con el siguiente gráfico:
# Importamos las bibliotecas necesariasimport numpy as npimport matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3D# Creamos vectores 3D para 10 palabras diferentespalabras = {‘Amor’: np.array([2, 9, 8]),‘Odio’: np.array([8, 7, 1]),}# Creamos la figura y el objeto Axes3Dfig = plt.figure()ax = fig.add_subplot(111, projection=’3d’)# Graficamos los vectores 3Dcolores = [‘r’, ‘g’, ‘b’, ‘c’, ‘m’, ‘y’, ‘k’, ‘orange’, ‘purple’, ‘brown’]for i, (palabra, vector) in enumerate(palabras.items()):ax.quiver(0, 0, 0, vector[0], vector[1], vector[2], color=colores[i], label=palabra)ax.set_xlim([-1, 10])ax.set_ylim([-1, 10])ax.set_zlim([-1, 10])ax.set_xlabel(«Formalidad»)ax.set_ylabel(«Frecuencia de uso»)ax.set_zlabel(«Positividad»)ax.set_title(«Representación gráfica de vectores 3D para propiedades de 10 palabras»)ax.legend()plt.show()

¡Fácil! ¡Sacamos el ángulo entre los dos vectores lo normalizamos dividiéndolo entre 180 para normalizarlo! Eso nos daría un número entre 0 y 1 donde cuanto más cerca de 0 más diferentes y cuanto más cerca de 1 más similares. ¿Verdad?
Sí, lo cierto es que sí, pero… ¿Cómo calculamos el ángulo entre dos vectores de más de mil dimensiones? Vaya vaya, parece que la cosa se nos complica…
Para eso existe una operación muy importante que usaremos mucho a lo largo del entendimiento de los transformers. Se trata del dot product (o producto escalar).
El dot product entre dos vectores normalizados da como resultado un número en el rango de -1 a 1 donde -1 indica que la dirección de los vectores es opuesta y 1 indica que son perpendiculares.
Por ejemplo, a continuación te muestro 12 vectores como si cada uno apuntase a una hora de un reloj y al lado de cada flechita te muestro el resultado del dot product entre cada vector con un vector que «apunte hacia arriba» (vector 0, 1)
# Importamos las bibliotecas necesariasimport numpy as npimport matplotlib.pyplot as plt# Función para rotar un vector en gradosdef rotar_vector(vector, angulo_grados):angulo_radianes = np.radians(angulo_grados)matriz_rotacion = np.array([[np.cos(angulo_radianes), -np.sin(angulo_radianes)],[np.sin(angulo_radianes), np.cos(angulo_radianes)]])return np.dot(matriz_rotacion, vector)# Vector inicial y vector de referencia (0, 1)vector_inicial = np.array([1, 0])vector_referencia = np.array([0, 1])# Graficamos los 12 vectores rotados y sus productos escalares con el vector (0, 1)for i in range(12):vector_rotado = rotar_vector(vector_inicial, i * 30)vector_rotado_normalizado = vector_rotado / np.linalg.norm(vector_rotado)dot_product = np.dot(vector_rotado_normalizado, vector_referencia)plt.quiver(0, 0, vector_rotado[0], vector_rotado[1], angles=’xy’, scale_units=’xy’, scale=1, color=’b’)plt.text(vector_rotado[0] * 1.1, vector_rotado[1] * 1.1, f»{dot_product:.2f}», fontsize=10)plt.xlim(-1.5, 1.5)plt.ylim(-1.5, 1.5)plt.xlabel(«Eje X»)plt.ylabel(«Eje Y»)plt.grid()plt.gca().set_aspect(‘equal’, adjustable=’box’)plt.title(«12 vectores en 2D y sus productos escalares con el vector (0, 1)»)plt.show()

Ok, ya entendemos qué hace la operación pero…¿Y cómo se calcula el producto escalar? El signo de la operación es «·».
Para un vector de N dimensiones donde nos referimos a cada parámetro como wn donde n es el índice de la dimensión. El producto escalar de los vectores previamente normalizados A y B sería:
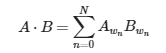
Embedding y tokenización: El proceso de «traducir» de palabra a vector.
¡Genial! Ya hemos entendido todo lo necesario para que una red neuronal nos entienda. Los grandes modelos de lenguaje, dicho de forma muy reduccionista son «simplemente» redes neuronales que reciben una secuencia de tokens como input y como output generan un vector donde cada valor número representa la probabilidad de que un determinado token sea la siguiente. Así es como escriben, y como entrenan. Tú te creas una red neuronal que reciba unos tokens (cada token siendo un vector que representa las características de una palabra). La red escupe el token más probable y de ahí generas la función de coste y haces backpropagation hasta que sepa completar textos. Pues aunque realmente es más complejo, la idea va por ese camino.
Ahora bien… ¿Cómo podemos hacer para pasar de una palabra a un token? ¿Voy a tener que puntuar miles de característica por cada palabra? ¿Y con las mayúsculas y minúsculas? Menuda faena…
No te preocupes, la clave está en delegar esta tarea a una red pbc neuronal.
Imagina que estamos trabajando con un modelo de lenguaje muy primitivo que solamente sabe expresarse con 5 palabras. Estas palabras son: «gustar», «mi», «no», «cosa», «hacer».
Con esto ya podríamos generar frases con un mínimo de sentido. «Mi gustar cosa», «Mi no gustar hacer cosa»… Muy primitivo pero ideal para una explicación.
Representaremos cada palabra con un vector categórico. Un vector categórico es un vector donde cada posición indica si el vector representa un elemento o no. Si lo representa, ese valor será 1 y si no 0. En el contexto de palabras, cada vector tendrá tantos números como palabras existan en el vocabulario. Y todos los valores serán 0 excepto 1.
Por ejemplo podemos realizar la siguiente asignación de vectores:
- La palabra «gustar» será el vector (1,0,0,0,0).
- La palabra «mi» será el vector (0,1,0,0,0).
- La palabra «cosa» será el vector (0,0,1,0,0).
- La palabra «hacer» será el vector (0,0,0,1,0).
- La palabra «no» será el vector (0,0,0,0,1).
Generar algorítmicamente esta asociación es muy sencillo, y ahora podríamos usar ese vector como capa de input de nuestra red neuronal. Donde hay 5 neuronas y si la red neuronal recibe como input la palabra «gustar», la primera neurona recibirá como valor 1 y el resto 0.
Genial, ¡Ya sabemos cómo enviar palabras a la red neurona! Pero recuerda que la finalidad de esta red neuronal no es en sí predecir el siguiente token, sino obtener un token enriquecido con propiedades de cada palabra. Por ejemplo, imagina que el output de la red como output tiene el vector de 3 dimensiones que utilizamos anteriormente para definir formalidad, positividad y frecuencia de las palabras. Bien, pues generalmente el output de esta red neuronal serán vectores de miles de dimensiones para convertir palabras representadas con tokens como «(1,0,0,0,0)» que no contienen información del significado de la palabra a tokens ricos en información.

Es de esta manera en la que cuando una red neuronal «oye» una palabra, entiende su significado y no es una secuencia aleatoria de caracteres.
Muy bien, pero todavía nos quedan algunas incógnitas por resolver… ¿Cómo entrenamos a esta red? ¿Cómo definimos las propiedades de cada palabra en el output? El output de esta red estará conectado al input de la red neuronal que sí pretende predecir el siguiente token de modo que al aplicar el backpropagation también en esta red, será el propio proceso de aprendizaje el que determine con la detección de patrones qué propiedades expresarán los tokens enriquecidos.
Para dar un poco de vocabulario técnico, los vectores tipo «(1,0,0,0,0)» se llaman tokens one-hot encoding. Y el proceso de transformar información en con datos redundantes a información relevante y condensada se le conoce como embedding. Por ello el proceso de convertir el vector «(1,0,0,0,0)» en el vector «(90% positivo, 50% formal, 99% frecuente)» se conoce como embedding. Hay más tipos de embeddings pero esos los conoceremos más adelante.

Y así es como GPT aprende palabras. Para él las palabras no son formadas por letras sino por propiedades que él mismo ha definido intentando predecir tokens. Es importante mencionar que realmente los tokens son secuencias de caracteres que no son exactamente las palabras de nuestro lenguaje.
Las palabras muchas veces tienen elementos en común. Por ejemplo, el plural de monstruo es «monstruo» + la letra «s». Un token realmente se asemeja más a una sílaba que a una palabra. ¿Y por qué? Bueno, pues porque así gpt puede encontrar patrones más complejos en el lenguaje y tiene mejor rendimiento. En toda mi explicación me he referido a tokens como representaciones de una palabra completa únicamente para simplificar la explicación.
¡Este es un gran paso para entender el funcionamiento de los transformers! Aunque aún nos queda mucho recorrido por delante. Voy a marcar en el esquema de arquitectura de los transformers lo que hemos aprendido hoy:

Para terminar con una conclusión didáctica, supongo que ahora entenderás por qué todo el mundo compara los diferentes modelos de lenguaje por la cantidad de parámetros. A más parámetros, mayor capacidad de vocabulario, mayor número de propiedades al realizar el embedding del input y por tanto mayor número de patrones a analizar por parte de la red. A más patrones a detectar, puedes tener una red más grande sin overfitting y por tanto más inteligente. De ahí que todo el mundo mida las predicciones de las capacidades de los nuevos modelos de lenguaje en función de su cantidad de parámetros.
¡Enhorabuena! Ya has ganado la primera batalla para comprender a los transformers. ¡Que continue la conquista!