¿Qué es el Overfitting?
Para comenzar a hablar de overfitting debemos recordar cuando en el artículo anterior mencionamos que en el aprendizaje profundo, la implementación de redes neuronales y la elección de técnicas avanzadas de procesamiento de datos como matrices, paralelismo y optimizadores son clave para el éxito del modelo.
Sin embargo, incluso con la mejor selección de herramientas, existe un problema común que afecta la precisión del modelo y su capacidad para generalizar: el overfitting o sobreajuste.
En este artículo, exploraremos algunas de las técnicas más efectivas para prevenir y solucionar el sobreajuste. Aprender a evitar el sobreajuste es esencial para mejorar la eficiencia y la precisión de las redes neuronales garantizando que sean capaces de resolver problemas complejos de la vida real.
Let’s hit it. 🧠✨
[powerkit_toc title=»Table of Contents» depth=»3″ min_count=»4″ min_characters=»1000″ btn_hide=»false» default_state=»expanded»]
Repaso de capítulos anteriores tutorial de IA
Este post es el cuarto de una serie de artículos que forman el curso completo para aprender a trabajar con inteligencia artificial desde cero. Por ello te recomiendo que si no lo has leído, comiences por el primer artículo que te dará las bases para comprender mejor lo que explicaremos en los siguientes.
Los anteriores capítulos del curo tratan sobre:
Capítulo 1 – Tutorial inteligencia artificial
Capítulo 2 – Entendiendo las Redes Neuronales
Capítulo 3 – Uso de la Matrices para las Redes Neuronales
Ahora si, vamos a por el overfitting 👊
Explicación del Overfitting y soluciones
El overfitting ocurre cuando un modelo de aprendizaje automático, como una red neuronal, se ajusta demasiado bien a los datos de entrenamiento y no generaliza bien a datos nuevos. Esto significa que el modelo se ha «memorizado» los datos de entrenamiento y no es capaz de generalizar para hacer predicciones precisas en datos desconocidos. Las causas comunes del overfitting incluyen una cantidad insuficiente de datos de entrenamiento, un modelo con demasiadas capacidades o una alta complejidad, y una mala selección de características.

Para prevenir esto, es muy importante dividir el dataset sobre el que entrenamos nuestra red y reservar un conjunto de datos que nos sirva para comprobar que la red neuronal es funcional con un conjunto de datos con el que no se ha entrenado. Básicamente, es como enseñar a sumar a la red neuronal y comprobar que ha aprendido a sumar haciéndole sumar números que nunca ha visto.
Claro está, esto tan solo nos sirve para detectar el problema. No para solucionarlo.
Solución 1: Dropout
La técnica de dropout consiste en desactivar aleatoriamente un porcentaje de neuronas en una red neuronal durante el entrenamiento, con el objetivo de evitar el overfitting. El proceso de desactivar aleatoriamente un subconjunto de neuronas se conoce como «dropout» y el porcentaje de neuronas que se desactivan se conoce como «tasa de dropout».
La idea detrás del dropout es evitar que una red neuronal dependa demasiado de cualquier neurona individual, ya que si una neurona es particularmente importante para el rendimiento del modelo, el modelo se volverá muy sensible a los cambios en esa neurona. Al utilizar el dropout pbc, se evita que cualquier neurona individual sea esencial para el rendimiento del modelo, lo que ayuda a evitar el overfitting.
En resumen, la técnica de dropout consiste en desactivar aleatoriamente un porcentaje de neuronas en una red neuronal durante el entrenamiento, esto ayuda a evitar que el modelo se ajuste demasiado a los datos de entrenamiento y generalice mejor a datos desconocidos.
Solución 2: Regularizadores
Conforme más memoriza una red, más extremos y dispares son los pesos de las conexiones. Ésto es fácil de visualizar si se imagina un modelo que memoriza muchos casos posibles o que distingue un patrón. Si tienes problemas para visualizarlo, puedes comprobarlo entrenando un modelo y comprobar que, conforme mejor funciona con el dataset de entrenamiento y peor para el de validación, más se cumple la afirmación. La regularización consiste en tratar de mantener un valor regular en los pesos/bias de la red neuronal para penalizar el overfitting.
Existen 2 formas de regularización, la L1 y la L2.
L1 consiste en añadir un coste adicional a la función de coste en función de la magnitud de los pesos/bias.
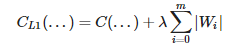
Donde λ es el impacto de la penalización.
L2 consiste en exactamente lo mismo pero de manera exponencial:
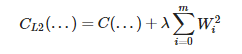
¿Y cuál de los dos funciona mejor? Bueno, de eso hablaremos más adelante.
Solución 3: Capas más pequeñas que el input en la estructura de la red
Es mucho más probable que se produzca la memorización si las capas ocultas de la red son de las mismas dimensiones (o mayores) que la capa de input. Si al menos una de las capas es más pequeña, el volumen de los estímulos es reducido en cierto punto y por ende la memorización es menos probable. Por ende el número de capas también puede influir. Debemos intentar que las dimensiones de nuestra red pbc se ajuste a la complejidad de la tarea a aprender pero no exceda la cantidad necesaria de neuronas. Hablaremos del criterio iterativo que se utiliza para determinar el tamaño de una red neuronal en el futuro.
Solución 4: Data augmentation
A mayor dataset, menor probabilidad de overfitting. Es como estudiar matemáticas. Cuantas más problemas resuelves, más vas entendiendo los patrones y menos memorizas.
Data augmentation es una técnica utilizada para aumentar el tamaño de un conjunto de datos de entrenamiento mediante la modificación de las muestras existentes en el conjunto de datos. Se usa principalmente para imágenes. Si tú tienes 10 imágenes de gatitos, probablemente si las escalas, rotas y transladas un poquito puedes obtener variantes que te sirven para entrenar la red.
Solución 5: Early stopping
Generalmente durante el entrenamiento siempre vamos a llegar a un punto donde tengamos overfitting. El early stopping consiste básicamente en parar de entrenar la red cuando detectes que su rendimiento con el dataset de entrenamiento mejora pero con el de validación empeora.
Cómo construir una red neuronal
Todo lo que hemos visto hasta ahora nos sirve para entender cómo funcionan las redes neuronales por dentro. Pero lo cierto es que nosotros no nos preocupamos de contruir desde 0 las redes neuronales. Existen diferentes tecnologías en el mercado que nos permiten decir «haz una red neuronal con 3 capas, cada una con x neuronas, ponme un dropout del x%, usa tales funciones de activación, tales regularizadores…» En definitiva, crear una red neuronal en el mundo profesional es como hacer una lista de la compra. A mí en particular me gusta mucho Keras para los primeros pasos por su sintaxis.
Ahora bien… ¿Qué criterios seguimos para tomar esas decisiones? ¿Cómo hago para saber cuántas capas necesito? ¿Y la función de activación? ¿Y el porcentaje de dropout? ¿Y los regularizadores? ¿Y el optimizador? ¿Y, tiene cada capa parámetros diferentes?
Bueno…